LLM as a reasoning agent
— Reasoning Models, Reinforcement Learning — 5 min read
Artificial Intelligence (AI) has witnessed unprecedented exploration and advancement of Large Language Models (LLMs) over the past two years. LLMs have progressively evolved to handle increasingly sophisticated tasks such as programming and solving advanced mathematical problems. Reasoning models like OpenAI's o-series model and Deepseek's R1 models, demonstrates generating very long reasoning process and conduct human-like reasoning actions like clarifying and decomposing questions, reflecting and correcting previous mistakes, exploring new solutions when encountering failure modes.
Performance of reasoning models consistently improves with increasing the computation of reinforcement learning and inference. This denotes 2 paradigm shifts
- From (self-)supervised learning toward reinforcement learning
- From scaling solely training computation to scaling both training and inference computation.
Background
Let us introduce some background of reinforcement learning and its connection to LLM in this section. Unlike other learning paradigms, reinforcement learning learns through interaction with the environment, rather than learning from a static training dataset. In reinforcement learning, an agent learns by receiving rewards from the environment as it explores. The below figure illustrates the interaction between agent and environment in reinforcement learning for LLM.
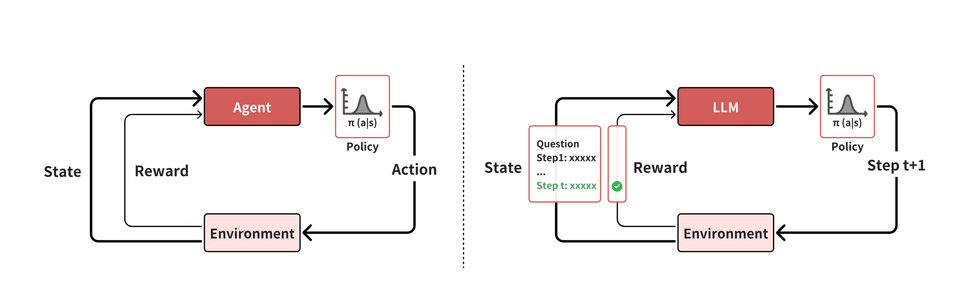
The visualization of the interaction between agent and environment in reinforcement learning for LLMs. Left: traditional reinforcement learning. Right: reinforcement learning for LLMs. The figure only visualizes the step-level action for simplicity. In fact, the action of LLM can be either token-, step-, or solution-level.
Agent
Agent is the entity that interacts with environment, which makes decision according to its policy. Formally, a policy π is a mapping from states to actions. It is often represented as a probability distribution (π(a|s)) over actions given a state s, where the agent selects actions based on these probabilities.
In the context of LLMs, an agent refers to LLM itself, its policy specify the probability distribution of either token-, step-, or solution-level actions based on the current state. The state st consists of the input provided to the model at time t, including both user inputs and the model’s earlier outputs. The action taken by the model can vary depending on the problem setting; it involves generating a single token, completing a step, or providing a solution.
Environment
Environment refers to the system or world outside the agent. It responds to agent’s actions and provide feedback in terms of next state st+1 and rewards r(st, at)
Environmental feedback can be categorized as either deterministic or stochastic. Stochastic feedback is characterized by a transition distribution p(st+1, rt+1|st, at), as seen in systems like dialogue models, where user responses are inherently unpredictable. On the other hand, deterministic feedback involves no randomness, yielding a fixed next state st+1 and reward r(st, at). For instance, when a LLM solves a mathematical problem, the transition is deterministic, where the current state st and action at are combined to produce the next state st+1.
LLM as a policy
Policy Initialization
Training an LLM from scratch using reinforcement learning is exceptionally challenging due to its vast action space. Fortunately, we can leverage extensive internet data to pre- train a language model, establishing a potent initial policy model capable of generating fluent language outputs. Moreover, prompt engineering and supervised fine-tuning help models acquire human-like reasoning behaviors, enabling them to think systematically and validate their own results. These approaches enable models to thoroughly explore their solution spaces, leading to more comprehensive problem-solving capabilities.
Reward Design
Both search and learning require guidance from reward signals to improve the policy. There are different levels of action granularity, each corresponding to varying levels of reward signals granularity, which can be explored further. Additionally, these signals are often sparse or even nonexistent in many environments. To transform sparse outcome reward to dense process reward, there are some reward shaping methods Ng et al., 1999. For the environment where the reward signal is unavailable, like the task of story writing, we can learn a reward model from preference data Bai et al., 2022a or expert data Ng & Russell, 2000. The construction of reward model can further evolve into building a world model Dawid & LeCun, 2023.
Search
Search plays a crucial role during both the training and testing phases. The training time search refers to generating training data from search process. The advantage of using search to generate training data, as opposed to simple sampling, is that search yields better actions or solutions—i.e., higher-quality training data—thereby enhancing learning effectiveness. During inference, search continues to play a vital role in improving the model’s sub-optimal policies. For instance, AlphaGo Wan et al., 2024 employs Monte Carlo Tree Search (MCTS) during testing to enhance its performance. However, scaling test-time search may lead to inverse scaling due to distribution shift: the policy, reward, and value models are trained on one distribution but evaluated on a different one Gao et al., 2023.
Learning
Learning from human-expert data requires costly data annotation. In contrast, reinforce- ment learning learns through interactions with the environment, eliminating the need for expensive data annotation and offering the potential for superhuman performance. In this roadmap, reinforcement learning utilizes data generated by search for learning via policy gradient or behavior cloning. Policy gradient methods have high data utilization, as they leverage both positive and negative solutions, whereas behavior cloning is advantageous in terms of simplicity and memory efficiency. A prominent example of the iterative interaction between search and learning is AlphaGo Zero (Silver et al., 2017, which combines Monte Carlo Tree Search (MCTS) (Metropolis & Ulam, 1949) as the search algorithm with behavior cloning as the learning method, ultimately achieving superhuman performance in the game of Go.
References
[1] Nicholas Metropolis and Stanislaw Ulam. The monte carlo method. Journal of the American statistical association, 44(247):335–341, 1949.